wan-gguf
Author: calcuis
Downloads: 16,947
Likes: 187
License: Apache 2.0
Created: Feb 26, 2025
Last Modified: Jul 8, 2025
gguf quantized version of wan video
- drag gguf to >
./ComfyUI/models/diffusion_models - drag t5xxl-um to >
./ComfyUI/models/text_encoders - drag vae to >
./ComfyUI/models/vae
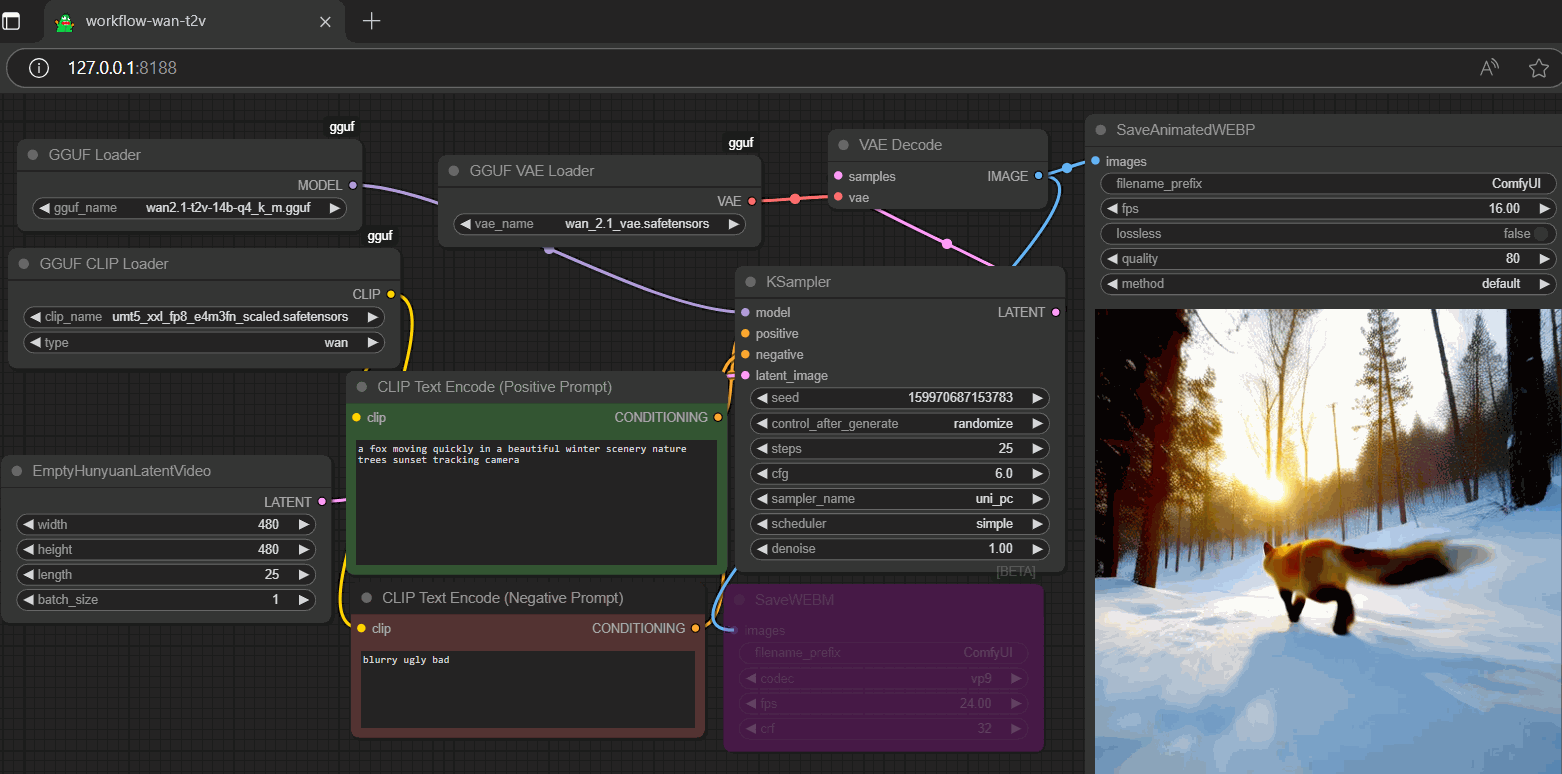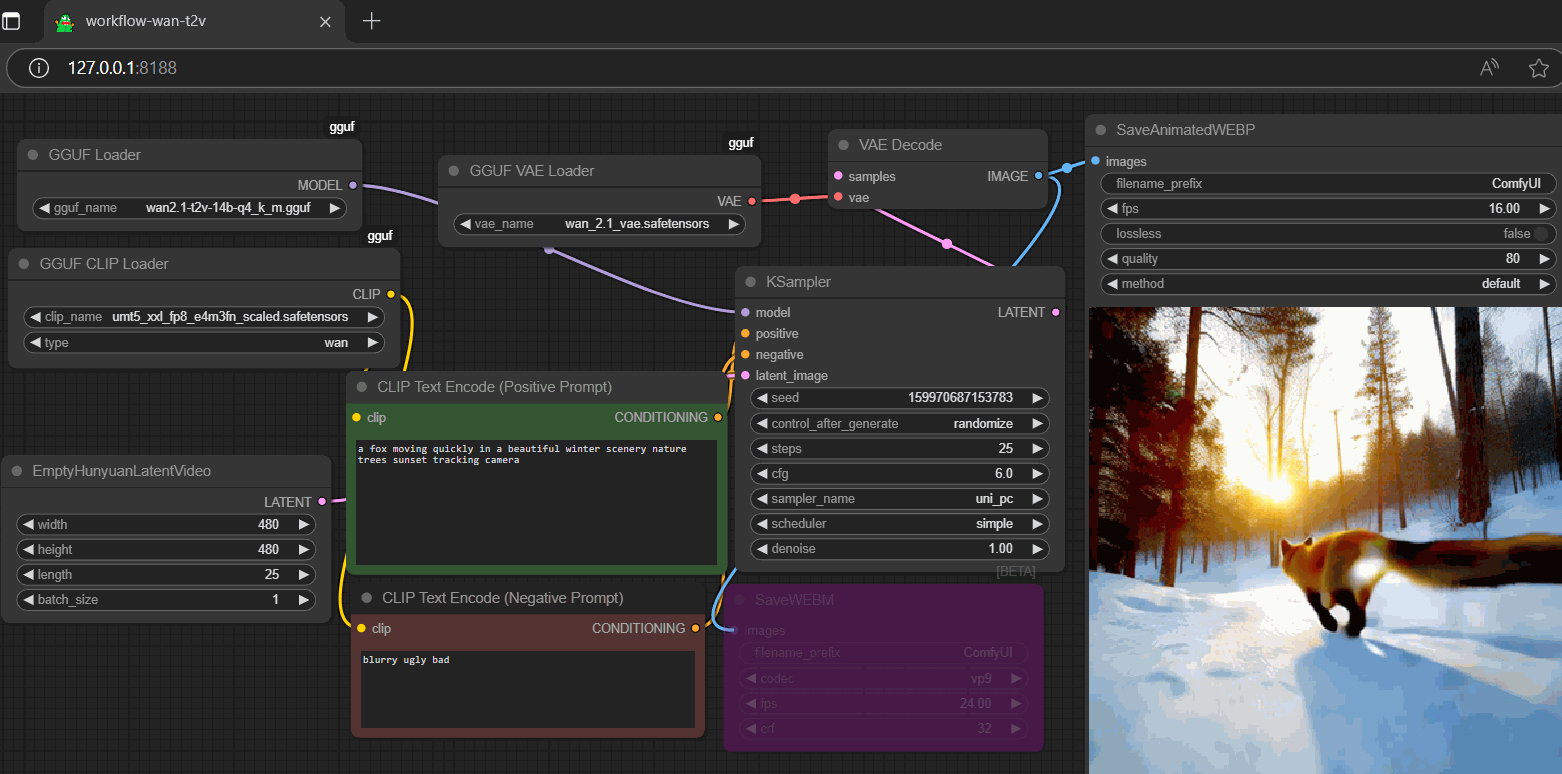
workflow
- for i2v model, drag clip-vision-h to >
./ComfyUI/models/clip_vision - run the .bat file in the main directory (assume you are using gguf pack below)
- if you opt to use fp8 scaled umt5xxl encoder (if applies to any fp8 scale t5 actually), please use cpu offload (switch from default to cpu under device in gguf clip loader; won't affect speed); btw, it works fine for both gguf umt5xxl and gguf vae
- drag any demo video (below) to > your browser for workflow
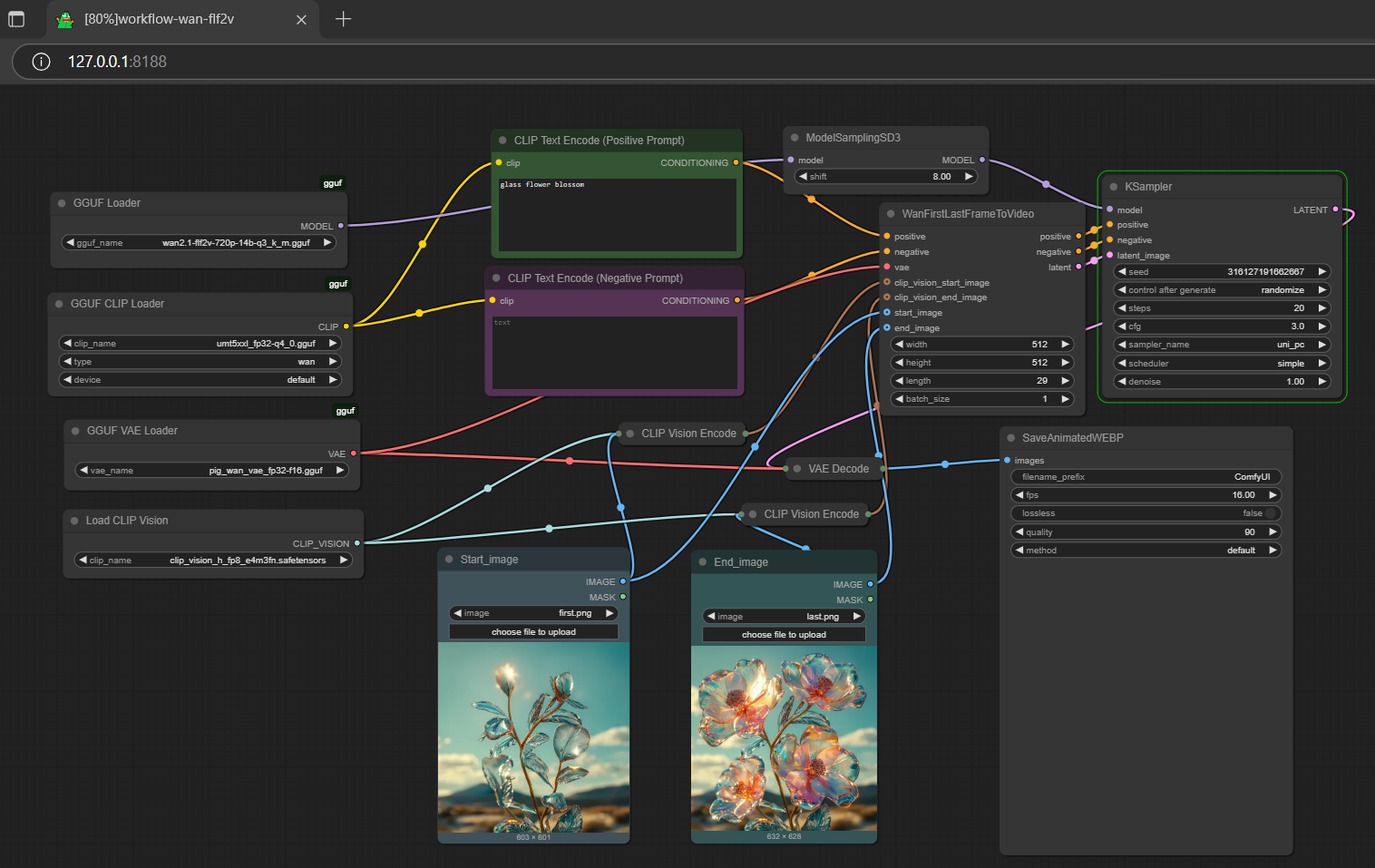
review
pigis a lazy architecture for gguf node; it applies to all model, encoder and vae gguf file(s); if you try to run it in comfyui-gguf node, you might need to manually addpigin it's IMG_ARCH_LIST (under loader.py); easier than you edit the gguf file itself; btw, model architecture which compatible with comfyui-gguf, includingwan, should work in gguf node- 1.3b model: t2v, vace gguf is working fine; good for old or low end machine
run it with diffusers🧨 (alternative 1)
import torch
from transformers import UMT5EncoderModel
from diffusers import AutoencoderKLWan, WanVACEPipeline, WanVACETransformer3DModel, GGUFQuantizationConfig
from diffusers.schedulers.scheduling_unipc_multistep import UniPCMultistepScheduler
from diffusers.utils import export_to_video
model_path = "https://huggingface.co/calcuis/wan-gguf/blob/main/wan2.1-v5-vace-1.3b-q4_0.gguf"
transformer = WanVACETransformer3DModel.from_single_file(
model_path,
quantization_config=GGUFQuantizationConfig(compute_dtype=torch.bfloat16),
torch_dtype=torch.bfloat16,
)
text_encoder = UMT5EncoderModel.from_pretrained(
"chatpig/umt5xxl-encoder-gguf",
gguf_file="umt5xxl-encoder-q4_0.gguf",
torch_dtype=torch.bfloat16,
)
vae = AutoencoderKLWan.from_pretrained(
"callgg/wan-decoder",
subfolder="vae",
torch_dtype=torch.float32
)
pipe = WanVACEPipeline.from_pretrained(
"callgg/wan-decoder",
transformer=transformer,
text_encoder=text_encoder,
vae=vae,
torch_dtype=torch.bfloat16
)
flow_shift = 3.0
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config, flow_shift=flow_shift)
pipe.enable_model_cpu_offload()
pipe.vae.enable_tiling()
prompt = "a pig moving quickly in a beautiful winter scenery nature trees sunset tracking camera"
negative_prompt = "blurry ugly bad"
output = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
width=720,
height=480,
num_frames=57,
num_inference_steps=24,
guidance_scale=2.5,
conditioning_scale=0.0,
generator=torch.Generator().manual_seed(0),
).frames[0]
export_to_video(output, "output.mp4", fps=16)run it with gguf-connector (alternative 2)
ggc v2
update
- wan2.1-v5-vace-1.3b: except block weights, all in
f32status (avoid triggering time/text embedding key error for inference usage)
reference
Share this model
Found this model useful? Share it with others!